
In text-data analysis, there is a hierarchy of processes through which we can obtain meaningful information from words, sentences, paragraphs, and even larger formats. At the document level, one may understand the underlying information by analyzing its content and more specifically, its topics.
The process of learning, recognizing, and extracting these topics across a collection of documents is called topic modeling. In topic modeling, documents are partitioned into many segments (topics), which may overlap with each other. Topic modeling is a type of statistical modeling for extracting hidden information that occurs in a collection of documents. The most popular techniques are LSA[1], LDA[2], and pLSA[3]. One of the recent promising techniques is lda2vec[4], which leverages both LDA and word2vec to make semantic topics more inoperable and supervised.
All of the topic modeling techniques mentioned above have the same underlying assumptions: each document consists of a mixture of topics, and each topic consists of a collection of words. In other words, topic models are built around the idea that the semantics of our document are being governed by hidden or latent variables that we are not observing. As a result, the goal of topic modeling is to uncover these latent topics that shape the meaning of documents and corpus.
However, the existing topic modeling algorithms have some limitations. For example, we have to determine the number of topics in advance which is not possible in many cases. The models are also sensitive to the input data processes, like small changes in stemming and tokenization that may lead to creating a completely different topic. Not only that, topics need to be manually categorized and obtain a name for each category. This manual process may not be always accurate because of the presence of mixed content, requiring domain knowledge. Another limitation is that adding new content or documents can change the topic distribution significantly.
In this article, I propose a method based on Betweenness Centrality (BC)[5]. BC is a graph algorithm that detects the influential nodes over the entire graph network. The proposed method could be used as an alternative to topic/concept modeling also be able to solve the problems mentioned above. To show the effectiveness of the algorithm I used the 2016 presidential debate of Donald Trump and Hilary Clinton conversational text dataset.
The Proposed Algorithm
The central idea of this algorithm is based on the theory of Betweenness Centrality (BC). BC finds the influential nodes based on the shortest path between every pair of nodes in a connected graph. The number of the shortest paths that pass through a node determines the influence of that node. A node will have a higher BC weight if it frequently lies on the shortest paths. The influential nodes can be regarded as a topic. The keywords of each topic are the neighbors of the corresponding topic. Each topic further can be linked to multiple types of entities. An entity is defined as a group of words that are connected to a certain category or property. For example, all the words mentioned by Speaker-1 are regarded as Speaker-1 entity and similarly, Speaker-2 entity has a group of words mentioned by Speaker-2. If no speakers are considered, then all the words belong to a single group which is called the global entity. Node-to-Entity connections enable us to deduce complex relationships between words and entities, which is not possible by traditional topic modeling.

In this algorithm, a directed text graph G(𝛎, E) is developed based on the unique words, entities, and their relationships. Where 𝛎 is a set of nodes (word 𝛎^w⊆ 𝛎 and entity 𝛎^e⊆ 𝛎 and E is a set of the edges. Two types of connections exist: 1) E_1 is the set of edges that connects words with entities; while E_2 is a set of edges that connect a word with next word. Once the network is built, BC (g(𝛎)) is computed globally to find influential words in the corpus. Based on the BC weight and nature of the problem, it is possible to select any number of topics and their corresponding title. The maximum number of the topic can be equal to the number of unique words. Thus the proposed algorithm solves the problem of determining the number of topics in advance and the title of the topic would be the nodes name. Algorithm 1 shows the algorithm snippet.
Results
Data processing
Removing unwanted information from the text is vital for any Natural Language Processing work. To demonstrate the algorithm, I used a 2016 US presidential debate data set containing three debates worth of text data that took place between Hillary Clinton and Donald Trump on three dates in 2016, September 26th, October 4th, and October 9th. All the stop words and unnecessary words that are unessential for this study and punctuation are removed to isolate the desired information.
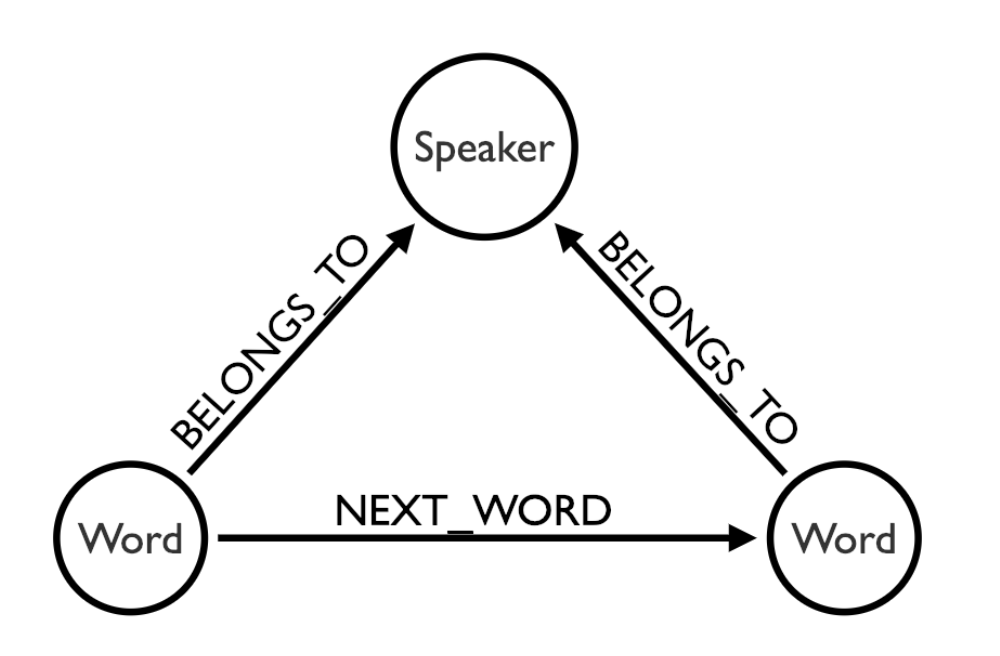
After processing the raw text, a graph network G(𝛎, E) has been developed using the community version of Neo4j 3.4.7. Where 𝛎 is a set of nodes and E is a set of edges. In the graph, two types of nodes exist 1. word (𝛎^w ⊆ 𝛎) and 2. entity (𝛎^e ⊆ 𝛎) where the entity is defined as a group of words mentioned by each speaker. For example, Speaker-1 and Speaker-2 are the entity that has their own overlapping words. Each unique word is connected to its next word and corresponding speaker. Figure-1 shows the data model of the text network. After the network is created, BC for each word and entity is computed.
Let's now discuss the details of the topics computed based on the BC.
Topic-entity relation

In this section, important words (topics) and their relation to an entity are discussed. Table-1 listed the top 25 influential words (topics) for different entities. The topics are ordered based on their BC weight. For example “job” in the global entity has the highest BC weight hence the most influential topic and “gun” has the lowest BC weight and therefore, least influential. The first global influential topic is “job.” Job creation was one of the most important topics during the campaign. Both of the candidates discussed their plan to expand job growth. After “job,” “women” and “business” were prominent topics. Tax reform was one of the important topics in the debates. Both candidates discussed their tax reform plans thoroughly. Beyond these issues, candidates discussed the middle-east crisis (Topics: ISIS, Iraq, Mosul, Syria), health care, gun rights, etc. This proposed algorithm identified these important topics from the corpus and solves the determination of the topic heading. The topics of both candidates are almost aligned with the global entity, with some minor order changes.

Both Speaker-1 and Speaker-2 have 21 topics in common, for example: "job", "women", "tax", and "health". Both Speaker-1 have their own four topics. Speaker-1 particularly discussed education, the role of Russian President Vladimir Putin in US politics, and the war in Iraq. Whereas Speaker-2 mostly emphasized Border security, job creation in the steel industry, reform health insurance, and business with China. In this model, there are two types of nodes, word, and entity (Speaker). The relationship between words and entities made it possible to extract information that you can't when using topic modeling.
The proposed algorithm also captures non-overlapped individualized topics. Figure-2 shows a Venn diagram that illustrates both overlapping and non-overlapping topics for the candidates. Speaker-1 and Speaker-2 have 21 common topics. One of the main benefits of this proposed algorithm is that it can separate topics that belong to a particulate candidate. For example, Speaker-2 discussed border security, job creation in the steel industry, reform existing health insurance policies, and trade deal with China. Speaker-2 heavily emphasized these topics. On the other hand, Speaker-1 discussed the role of Putin in the election. Speaker-1 directly accuses Russia of interfering with the US election[6]. The candidate's education plan was the vital topic of Speaker-1, followed by the crisis in the Middle East.
Topic Discussion
Table-2 lists the top six influential global topics with their betweenness centrality and neighbors. As discussed earlier, Job and Business are the most important topics. Both have similar BC weights. The neighbor of each topic provides us the context of the topic and the relationship among the other neighbors. For example, when the speaker discusses “Job,” they discuss incomes, wages, incentives, investments, job creation, the role of other countries in the US job sector. These are the neighbors of “Job” that reveal the context of the topic.
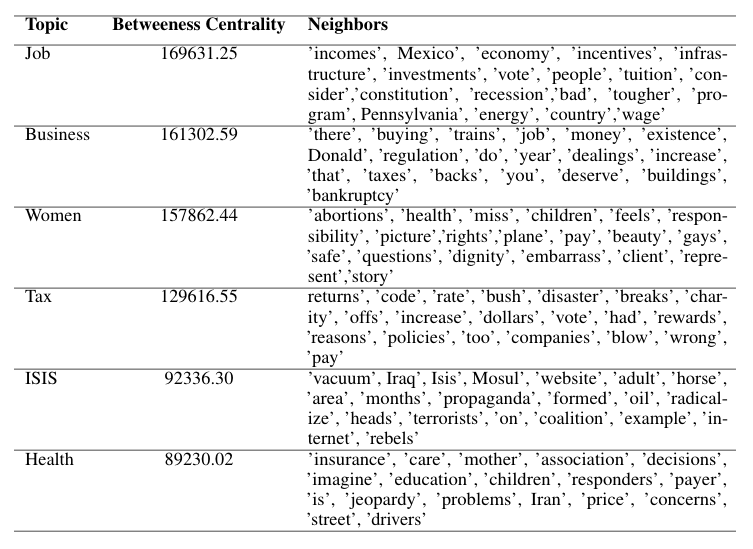
Similarly, when the speakers talk about Tax, they discussed tax returns, different tax codes, tax rates, tax breaks, tax policies, tax increases, etc... Health care has always been a critical topic in presidential elections. In, 2016 when speakers discussed health, they talked about the caveat of health insurance policies, health care reform, health education, etc. Similarly, we will be able to perform this type of analysis for topics too, even for each entity.
Conclusion
An alternative method of topic modeling is based on the famous graph theory of Betweenness Centrality. This algorithm detects influential nodes over the entire graph network. Applying the algorithm to the 2016 presidential debate conversation text data between Hilary Clinton and Donald Trump, this method was able to find the top topics that were discussed during the campaigns. Influential topics include "jobs", "business", "tax reform", "health", "the Middle East", and "border security". The algorithm is also able to separate candidate-specific topics. For example, "border security", "steel industry", "health care reform", and "trade dealings with China" were identified as Trump topics. Whereas, "the role of Putin in US politics", "education plan", and "the Middle East crisis" were identified as Clinton topics. The analysis demonstrates that this new method has the potential to detect meaningful information from the corpus.
References
[1] Thomas K Landauer, Peter W Foltz, and Darrell Laham. An introduction to latent semantic analysis. Discourse processes, 25(2-3):259-284, 1998.
[2] David M Blei, Andrew Y Ng, and Michael I Jordan. Latent dirichlet allocation. Journal of machine Learning research, 3(Jan):993-1022, 2003.
[3] Thomas Hofmann. Probabilistic latent semantic indexing. In ACM SIGIR Forum, volume 51, pages 211-218. ACM, 2017.
[4] Christopher E Moody. Mixing dirichlet topic models and word embeddings to make Ida2vec. arXiv preprint arXiv:1605.02019, 2016.
[5] Linton C Freeman. A set of measures of centrality based on betweeness. Sociometry, pages 35-41, 1977.
[6] Amy Chozick. Hillary Clinton Accuses Russia of Interfering With U.S. Election. The New York Times, 2016.