On Asurion’s Data Science Team, we leverage Machine Learning and Deep Learning to provide value to our partners and our customers. Whether it’s understanding messaging sessions, leveraging voice data or detecting fraud, machine learning models are ubiquitous behind the scenes. Understanding intent when our customers call/text us with their issues allows our experts to find better solutions more efficiently, and provide the right answers more often.
Parameters of a model refer to what the model learns from your data. In contrast, hyperparameters are not learned from data but are predetermined by the developer. For example, with a regularized linear regression model, the weights of the model are parameters, but the regularization coefficient is a hyperparameter of the model.
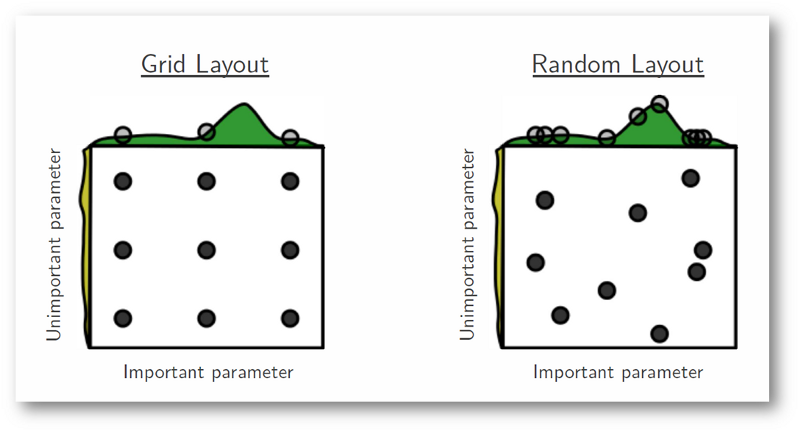
A model's performance is greatly determined by how well the hyperparameters are chosen. Achieving optimal performance can often be the difference between good and bad customer experiences. As models become more complex, it’s not uncommon to see hyperparameters in the range of tens to even hundreds. How can we ensure that we find the unique combination of hyperparameters that results in the best model performance? Well, we perform a hyperparameter search of course. Let's view two of the most common hyperparameter search algorithms —grid search and random search.
Grid Search
Grid search is the simplest form of hyperparameter search—or dumbest. Say you have 3 hyperparameters, each with 5 possible values they can take. You have a total of 5³ combinations of parameters, and a grid search will run all 125 combinations (exhaustive). If each hyperparameter had 6 combinations, the Grid search runs 6³ = 216 combinations. This is exponentially scaling and if your basic model takes 2 minutes to train, you’re looking at over 7 hours for grid search to complete! Parallelization (each hyperparameter search is done in parallel on one CPU core) can help to reduce the time to around 2 hours for a 4 core CPU. That is a long time to wait to optimize just three hyperparameters!
Random Search
Random search (http://www.jmlr.org/papers/volume13/bergstra12a/bergstra12a.pdf) is currently the de-facto standard for hyperparameter search. Let us continue with the example of 3 hyperparameters with 6 levels each. With random search, we pick the number of combinations to try (say 50) and the combinations of hyperparameters are picked at random. Astonishingly, Bergstra and Bengio showed that this performs as well as grid search. One of the key insights from their paper was that not all hyperparameters are created equal. Grid search wastes significant computation in which key hyperparameters are kept constant. Similar to grid search, random search also benefits from parallelization.
Conclusion
We have discussed two of the most common hyperparameter search techniques. To achieve the best possible results, the recommended strategy to use them is the following:
1. Use a random search to start the hyperparameter search.
2. Run grid search on a focused interval near where the best performance was obtained with random search to eke out any remaining bits of performance from your models.
3. Remember to parallelize the search process (set n_jobs = -1 in scikit-learn for example)!
There are other ways to optimize the hyperparameter search process, like Bayesian Optimization. We will explore this topic in a future article!